
티스토리 뷰
코멘토에서 라이브 PT - 'Firebase와 GA4로 사용자 데이터 수집하고 제품 개선하기' 수업을 들었다.
이에 대해 내용 복습 및 학습 일지 챌린지 참가를 위해 작성한다.
1. GA4와 UA의 차이점

UA는 오직 Web에서만 동작했지만, GA4는 앱과 웹 모두 작동한다는 것.
UA에서 사용하던 리소스(view)는 사라졌다.
GA4에서는 이를 대체하기 위해 스트림(Stream)이란 리소스를 만들었다.
Stream
- 데이터가 저장되는 곳, 데이터 조회의 대상
- 한 계정에 다수 속성 생성 가능(회사 계정에 00앱 속성 + 회사 소개 웹 속성 + 채용 안내 웹 속성)
2. 구글 마케팅 서비스의 조직 관리 기능 제공 - Google Marketing Platform Home
- 프로젝트의 규모가 커져 Google Ads, Analytics, Optimize, Tag Maganer, Survey, Data studio등을 같이 사용하게 될 경우, 서로 연동시켜 통합 관리가 가능한 서비스이다.
-각 서비스의 리소스별로 접근 권한을 제어
3. GA4 기본 정의 복습
(1) Hit - google Analytics에 전달되는 모든 데이터
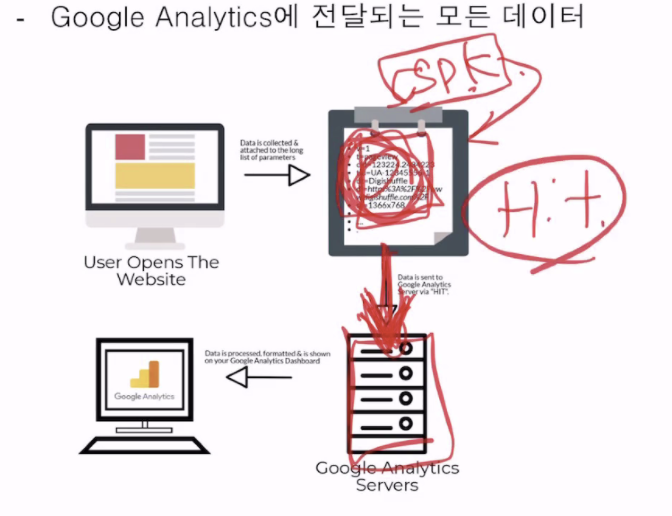
- 한 번의 리퀘스트에 들어가는 최소 단위의 정보( 가장 작은 이벤트 단위 )
- 히트가 GA 서버에 쌓이면 추후 리포트로 나오게 되는 것이다.
(2) User - Hit를 남긴 사람(사람!=기기)
-사용자 단위 식별자로 구분
-식별자 = 쿠키에 남겨진 임시 발급 고유 아이디 혹은 User ID
*웹은 쿠키로 고유 식별자 역할을 하며, 앱은 앱 설치 시 고유 번호를 발급한다.
- 그렇기에 한 사람이 하나의 기기가 아닐 수도 있다. 같은 식별자를 가졌지만, 회원가입하면 한 사람이거나 두 사람일 수도 있어서 섞일 수 있다.
-> 앱이 설치된 한 기기에 여러 사람이 사용해서 접속 할 수도 있고, 한 기기에서 같은 사람이 쿠키가 재설정이 되면 두 사람으로 인식 할 수도 있다. 또는 한 사람이 두 개의 기기를 가지고 있을 수도 있다.
그렇기에 한 사용자(=임시 발급 고유 아이디 = User ID = 식별자 = 유저)가 한 사람을 의미하는 것도, 한 개의 기기를 의미하는 것도 아니다.
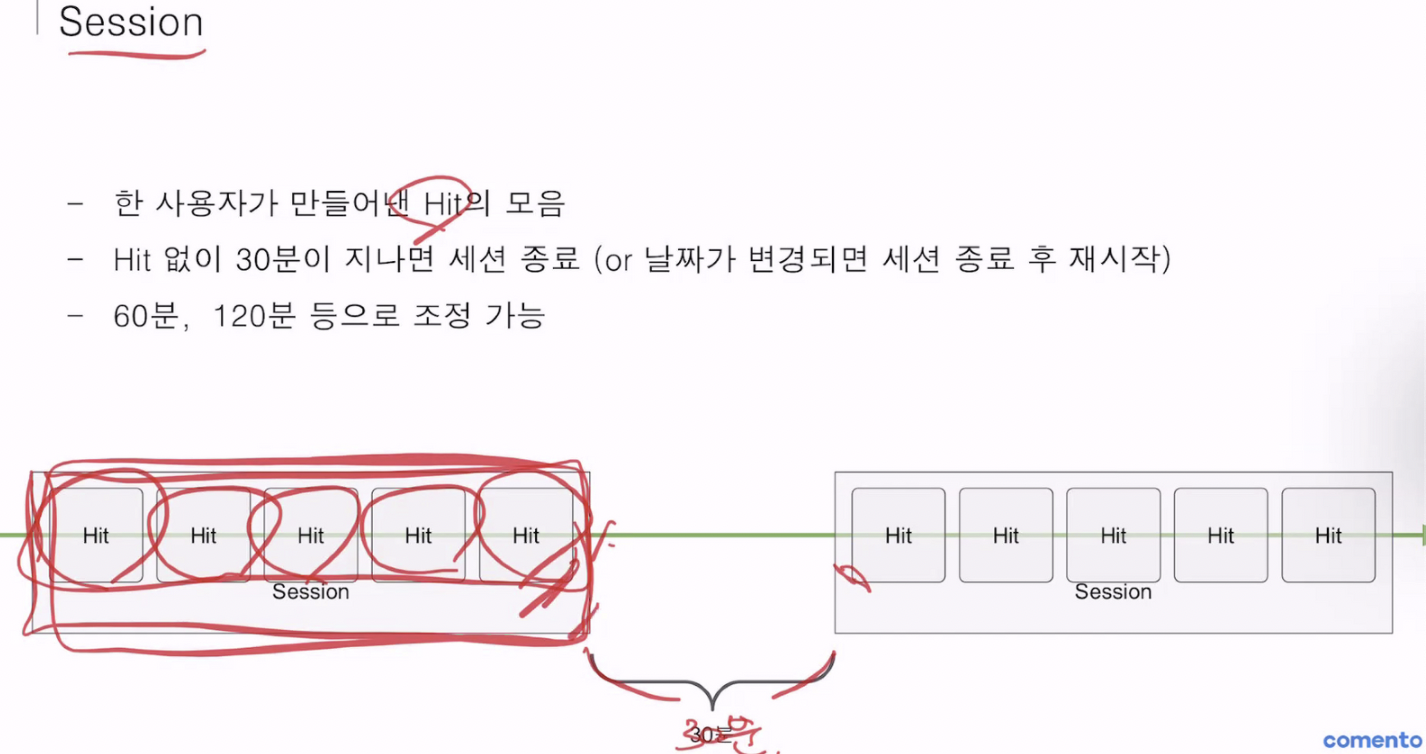
(3) Session - 한 사용자가 연속적으로 만들어낸 Hit의 모음
- 여러가지 조건 설정이 가능. (i.e Hit없이 30분이 지나면 세션 종료, 날짜가 변경되면 세션 종료 후 재시작, 10분 동안 hit가 없으면 세션 종료 등)
(4) Scope of hit
*이벤트 수준 범위
- 매 이벤트 마다 일일히 별도로 기록되는 정보들 (한 번 이벤트가 발생했을 때 1회성으로 기록 됨)
ex) 사용자가 페이지를 조회했는데, 지도 화면 이었다. 지도 화면에서 발생되는 히트를 모두 기록
- 매번 정보를 기록
- 일회성 기록
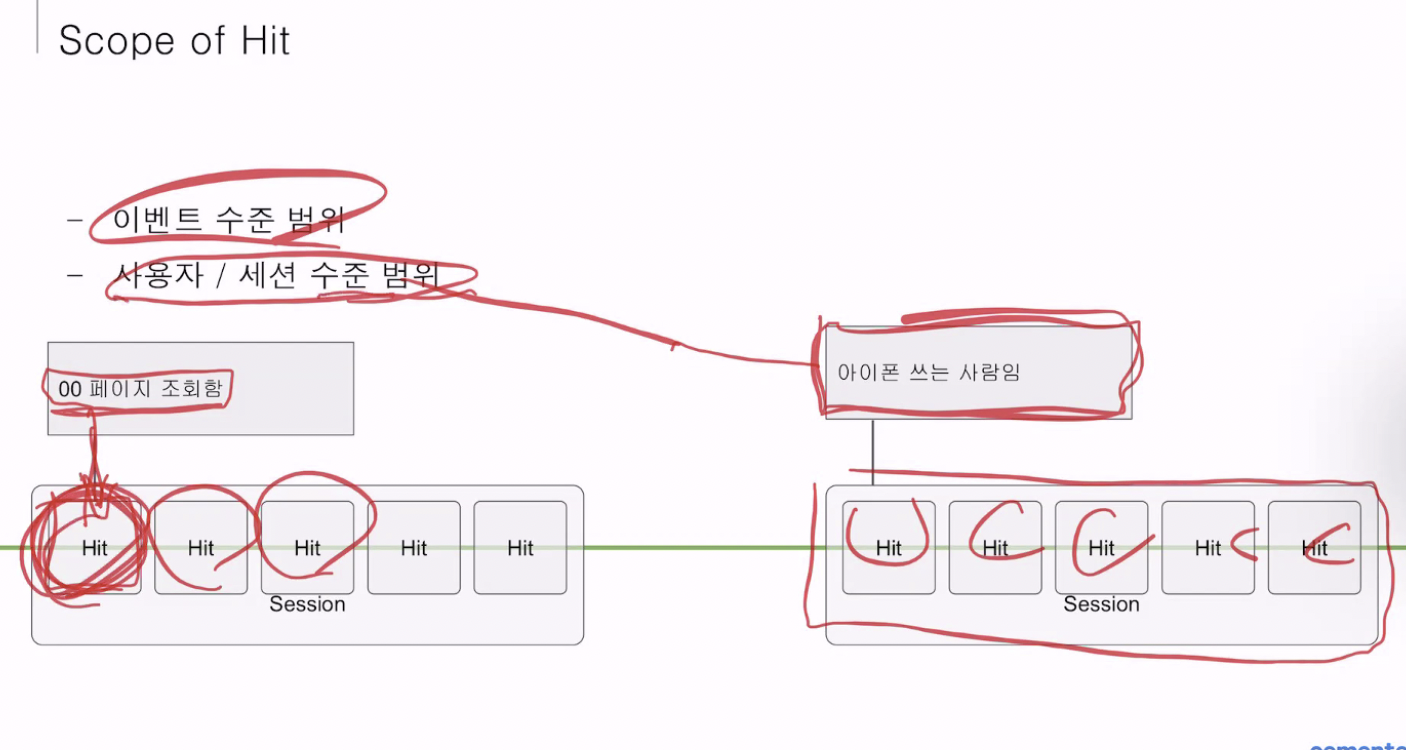
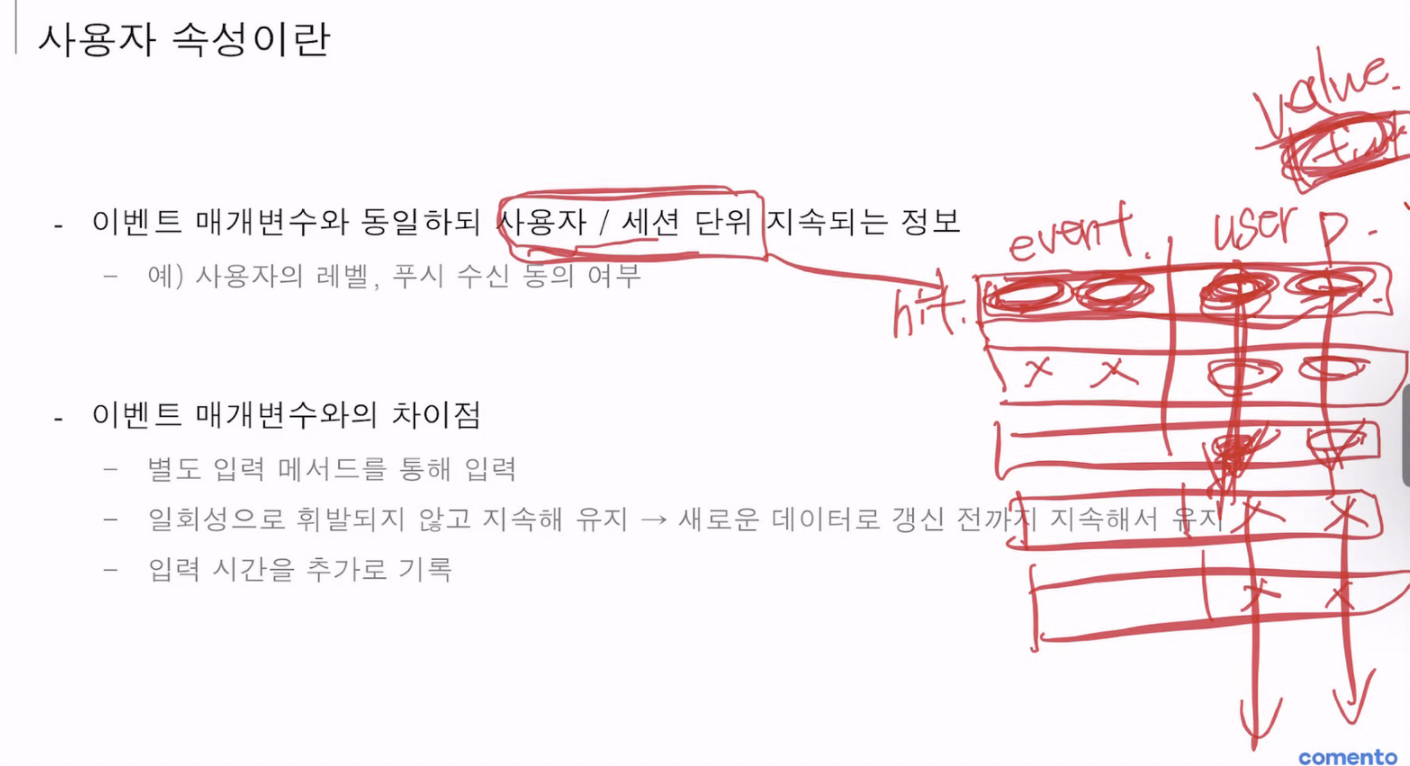
*사용자 / 세션 수준 범위
- 이벤트들이 연달아 일어날 때 특징을 한 번 심어주면 계속 달아주게 됨.
ex) 누가 들어왔는데 남자였다. 남자의 모든 히트 기록을 기록한다. 아이폰 쓰는 사람이 접속했다. 아이폰으로 작성되는 모든 히트를 기록한다.
- 정보 변경될 때 기록
- 계속 보관되어 유지되는 기록
- 데이터가 저장될때 사용자/세션 수준 범위를 설정할 경우 ‘아이폰 쓰는 사람'일 경우, 그들의 히트를 한번에 모아서 보여주고 보관한다.
(4) 태그 - 추적하려는 이벤트의 컨텍스트를 알 수 있는 메타 데이터
* 언제 , 어디에서, 어떤 일이 일어났는지 추적
(5) 태깅 - 태그(이벤트 데이터)를 저장하는 과정
-> 무슨 정보를 / 어디에 보낼지 / 어떻게 보낼지 결정
Tagging tools
- GA4 - gtag.js
- GA4 - Measurement Protocol
- Firebase Analytics SDK
- Google Tag Manager
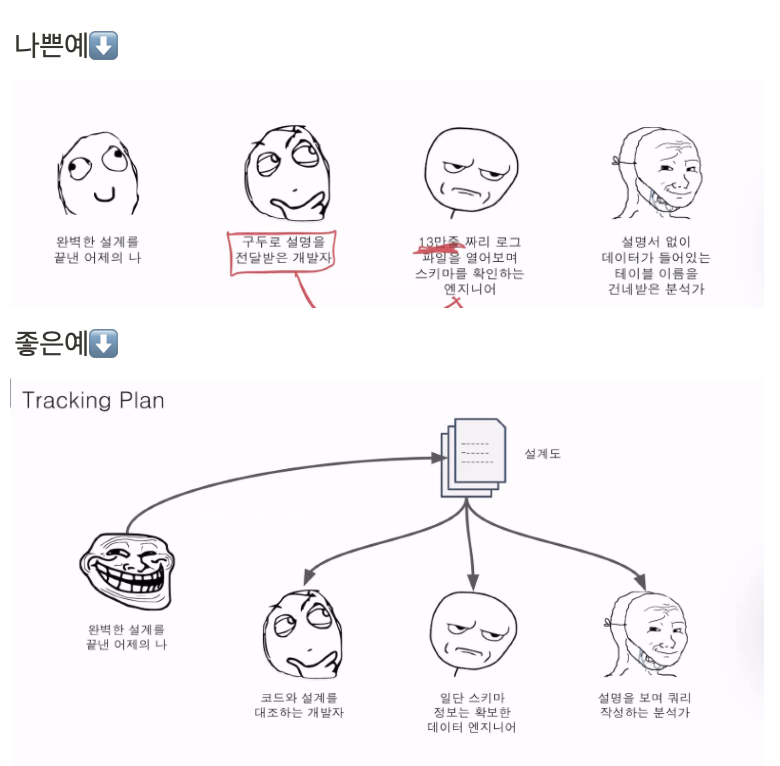
(6) Tracking Plan
- 말 그대로 태깅 계획
- 언제 / 어디에 / 어떤 / 무슨 정보를 태깅할지 계획하는 것
- GA4 기획자가 개발자와 분석자에게 정보를 전달하기 위한 도구 (* API 요구사항 정의서와 같다!)
- 그냥 GA4를 프로덕트에 사용하기 위해 각 팀들과 원활히 소통하기 위한 대쉬보드(또는 문서)라고 생각하면 된다.
트래킹 플랜 방식의 선택
- 사용하는 도구에 의존적
- 개발 조직의 리소스와 역량에 맞춰 선택
-starter
구글 스프레드 시트(현실적으로 가장 합리적인 선택)
-advanced
Amplitude & Snowplow
-Hardcore
Kafka
*gtag.js

*자동으로 수집되는 이벤트

*웹에서만 수집되는 이벤트
- 페이지 조회, 스크롤, 모든 클릭, 동영상(재생 시작, 진행, 완료)
**GA4에서는 페이지 로드 뿐만 아니라, url이 변경되는 것도 페이지 조회로 취급하게 되어서 모든 이벤트들이 잘 수집된다.
**앱 삭제는 IOS는 안되고, Android는 추적 가능하다.
스크린 전환은 코드 구현을 어떻게 하느냐에 따라 실제 추적이 가능 할 수도 있고 아닐 수도 있다.
→ IOS, Android 코드 구현에 따라 스크린 전환 이벤트를 확인 가능 할수도, 안될수도 있기에 처음 코드 짤때 잘 짜야 한다.
*자동으로 수집되는 사용자 정보
- 일회성 이벤트 외에 사용자 정보를 자동으로 수집
- 디바이스, 지역(ip 기반으로 도시 수준까지만 제공), 트래픽 소스, 익명 사용자 식별자
** 트래픽 소스 - utm 소스(미디엄, 캠페인, 아이디)를 타고 들어오는 사용자들. 특정 url에 파라미터를 들고 들어올 때 트래픽 소스로 식별해서 사용자 단위의 정보로 식별해서 추적.
❓모든 정보를 자동으로 수집한다면 편하지 않을까? - 서비스 개발(코드레벨) 설계 시작단계에서 부터 딥하게 인볼브 되어야 함으로 쉽지 않음.

(7) 이벤트 매개변수
GA4에서는 정보의 종류의 제한 없이 입력
- 하나의 이벤트에 [이벤트 이름, 이벤트 매개변수의 묶음]을 함께 기록
- 이벤트 매개변수는 '키'와 '값'을 쌍으로 가지는 배열 객체

*사용자 속성 - 이벤트 매개변수와 동일하되, 사용자 / 세션 지속되는 정보 (사용자의 레벨, 푸시 수신 동의 여부)
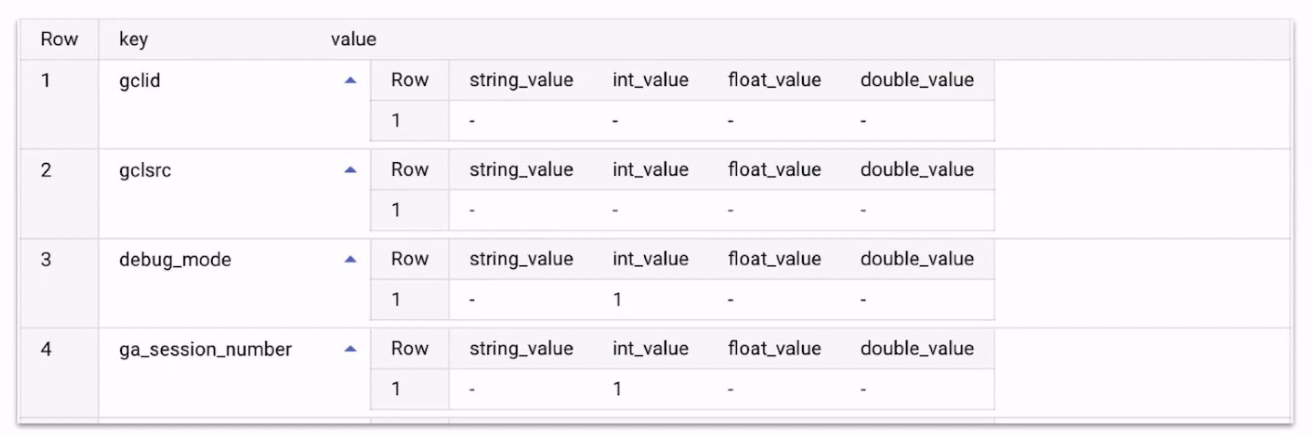
*이벤트의 종류는 500개가 제한
매개변수는 25개가 한계
키의 경우에 40글자, 값의 경우에 100글자 제한.
→ 그래서 많은 파라미터를 가지는url이 들어오게 될 경우 값 100자를 넘어가게 되면 에러가 발생함.

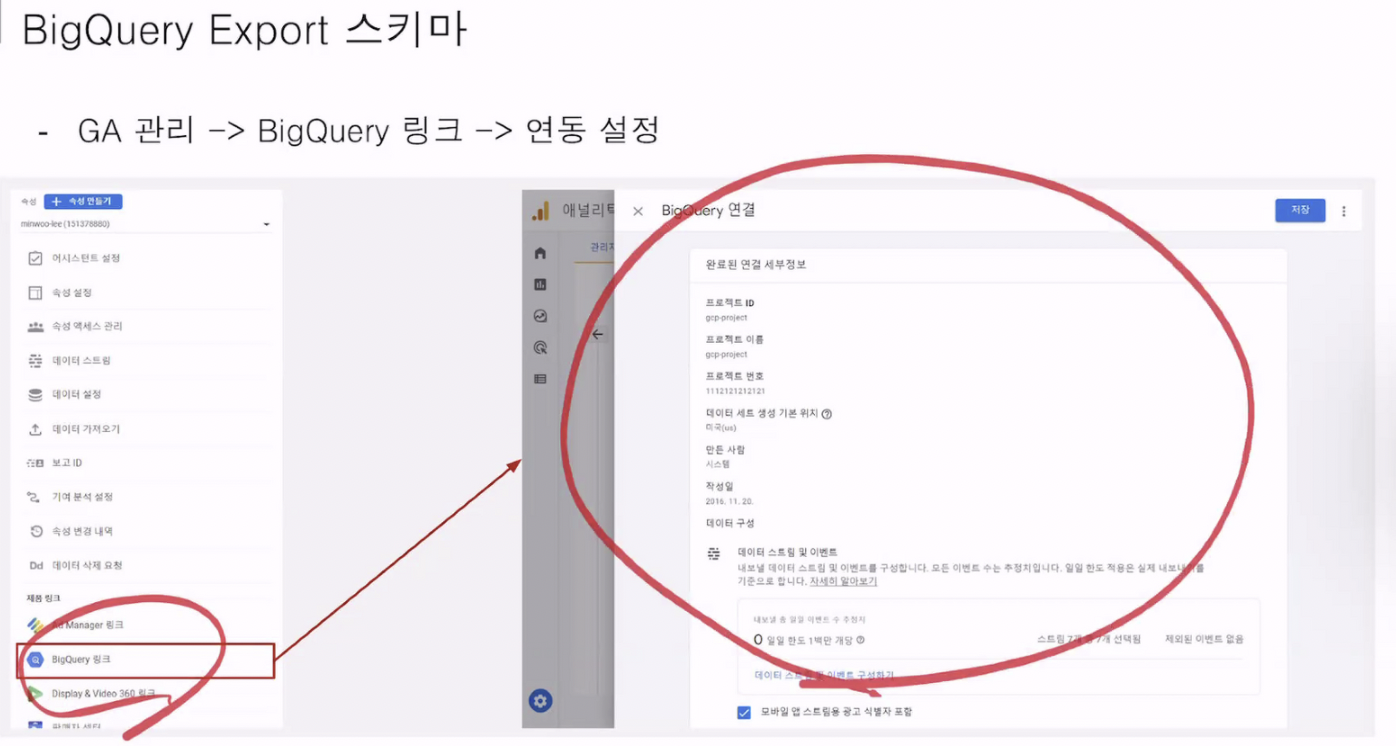
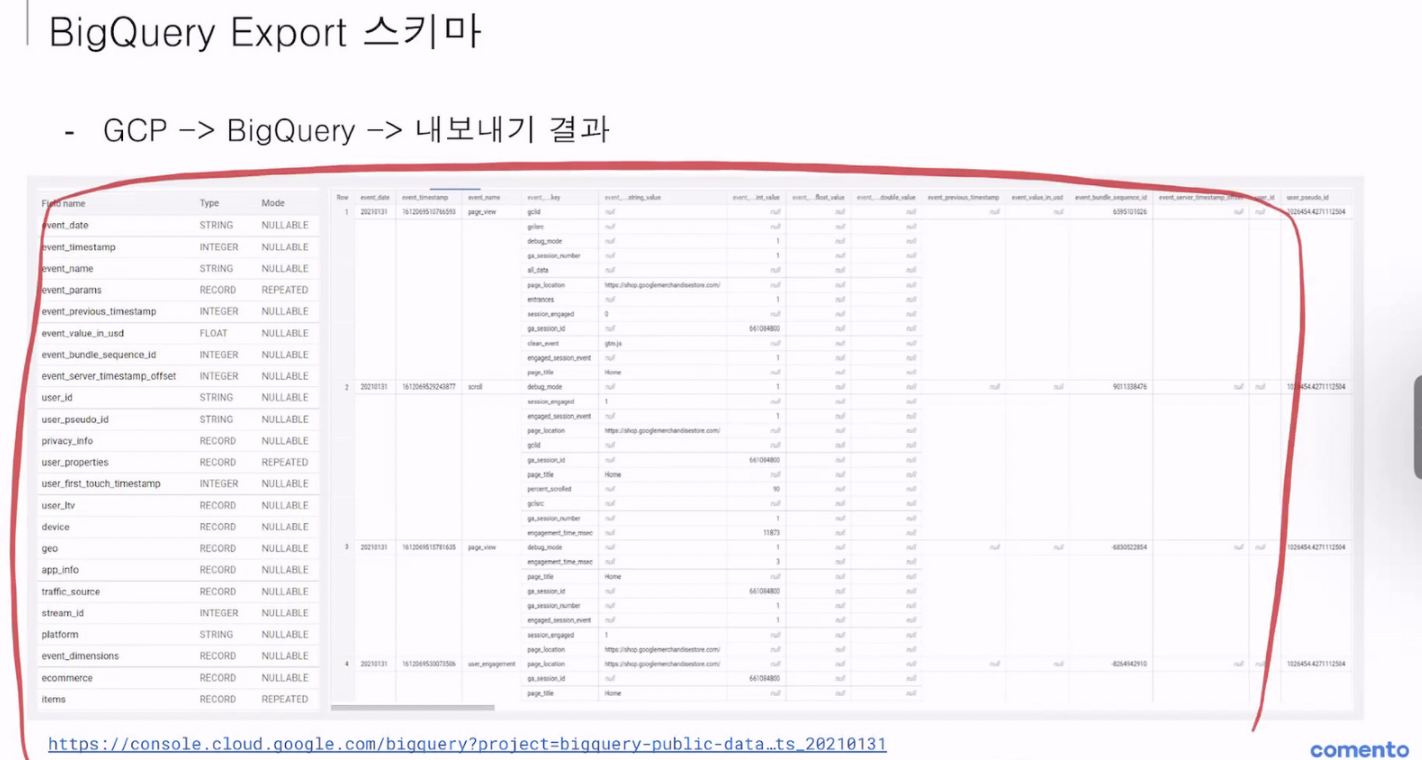
(8)Big Query Export 스키마(이부분은 이해 아직 못함..)

*추가 : SDK란?
SDK는 일종의 라이브러리이다. (나 또는 다른 사람이 만들어 놓은 코드 뭉치가 SDK 이며, 이를 나든, 남이든 사용 하는 것)
어떤 함수를 만들었다고 할 때 웹 페이지에 버튼이 클릭 되었을 때 팝업을 띄어라 라는 기능을 개발했다고 가정.
라이브 PT 강의에 관심 있으시면 아래 링크로 접속하시면 됩니다.
https://bit.ly/3D9XCOz
*본 영상은 라이브 PT 강의를 수강 후 환급을 위한 학습 일지 챌린지 참가 및 내용 복습을 하기 위해 작성한 글입니다.